As companies progress their Generative AI workloads towards a Production environment, they need to start considering how they can apply aspects of modern cloud governance to these workloads, such as security, cost optimisation, and observability.
Placing Azure API Management (APIM) in front of an Open AI service was already a good idea - It provides a centralised point to manage your Azure OpenAI credentials without having to distriute them across your organisation, and it provides load-balancing capabilities to manage traffic across different models, regions, or pricing models.
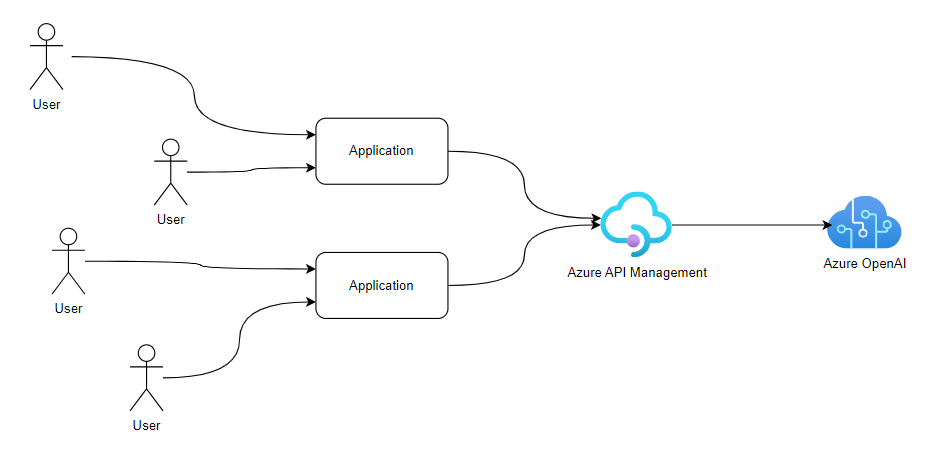
Recently, Microsoft announced some new Generative AI capabilities in Azure API Management that make the service even more useful for Generative AI workloads.
Pricing in Azure OpenAI is fundamentally constructed around ‘tokens’. Every request in and response out of an Azure Open AI service has a token count, and the more tokens you consume, the more you have to pay.
Out of the box Azure OpenAI lets you set a token-per-minute limit for a model deployment and provides metrics on token consumption - however, you cannot drill down on these metrics to see either per-user, or per-application details. This lack of ability to drill down can make it hard to understand how your workloads are consuming Generative AI, and hard to enable sensible controls.
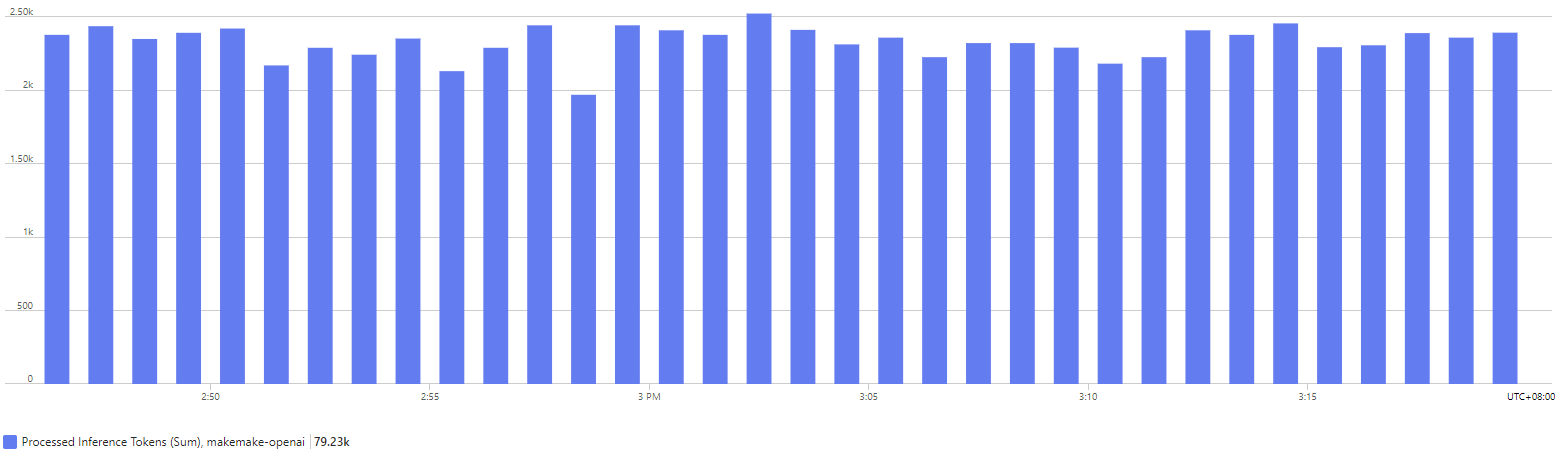
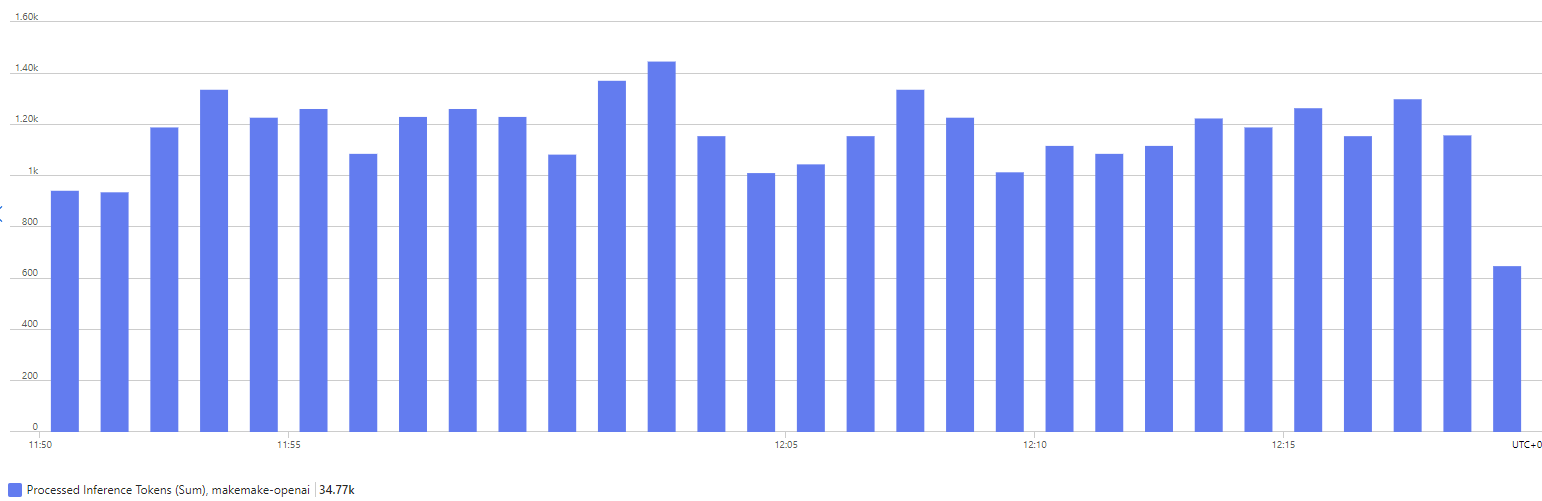
The chart below shows some sample traffic to an Azure OpenAI service over a 30 minute period. We can see overall token consumption, but not much else.
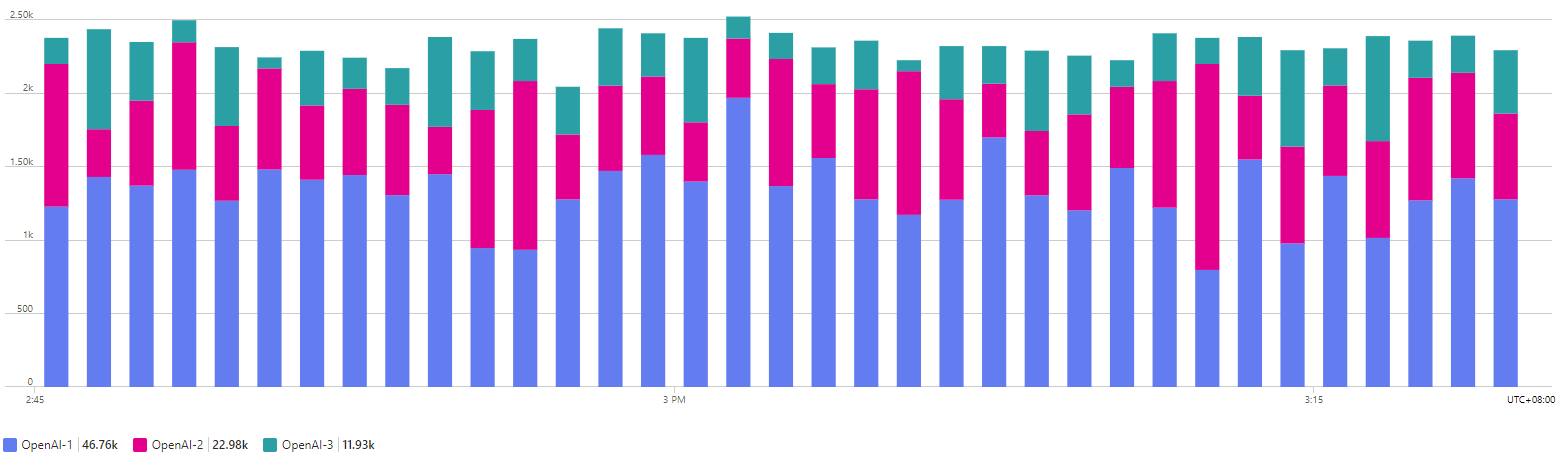
The first new Generative AI capability in Azure APIM is simply enhanced metrics. You can now easily view token usage at either the user or the application level.
Looking at the chart below, we can now drill down and see service usage per user. In this example, we can now see that over half of our OpenAI usage can be attributed to one user.
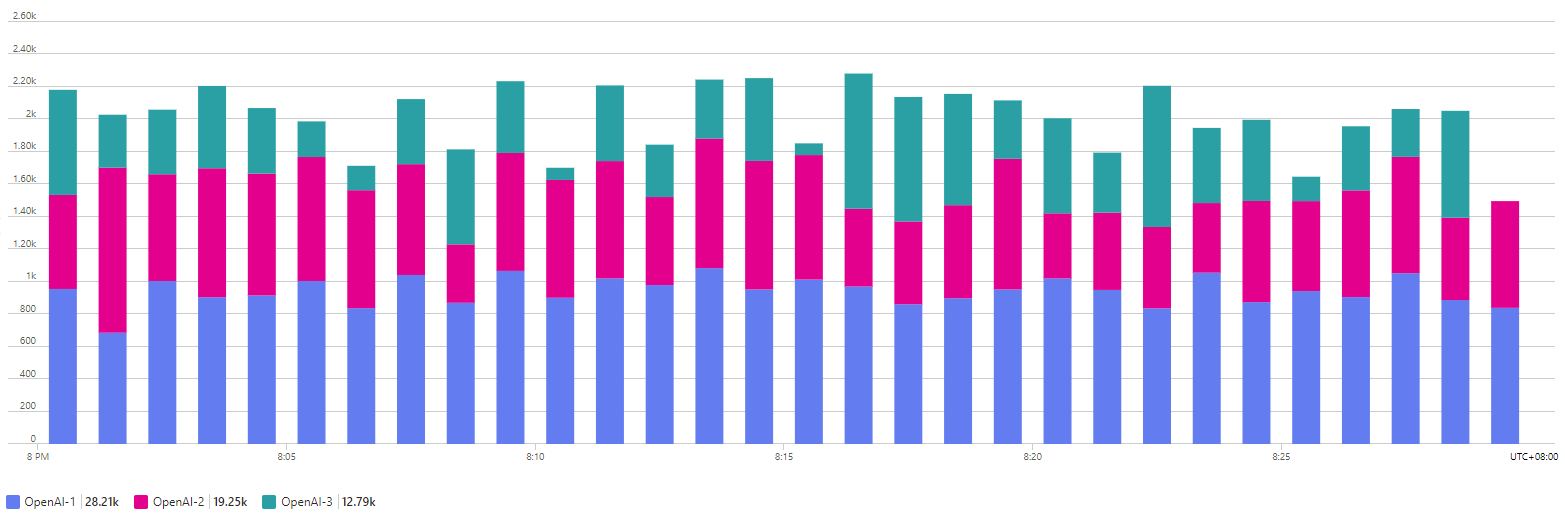
Taking this to the next level, there is now the ability to apply rate-limiting, also at either the user or the application level. This can help ensure that your total tokens assigned to your model are being shared around, and not being entirely consumed by one hungry user.
In this chart, the Azure APIM service is enacting a per-user rate limit of 1000 tokens/minute. We can see that the user with the largest usage has had their consumption limited, while the other users consumption levels are unaffected.
The next capability is a little more advanced, but fundamentally involves the ability to cache common requests in Azure API Management to avoid needing to use the Open AI service as much.
This may initially sound counter-intuitive for GenAI, as a lot of our individual experiences to date have been blank-page open-world style discussions across wide ranging topics with ChatGPT, but I think it is more relevant when you consider the types of Generative AI use cases that organisations generally implement.
Consider, for example, a public facing chatbot on a company’s website. The chatbot allows a customer to search over the company’s data, using the popular Retrieval Augmented Generation (RAG) pattern. This pattern takes a user’s request, uses the request to look up relevant data in a database, and then passes the user’s request and the database result into OpenAI to generate a user-friendly response.
If you have a lot of customers making very similar requests, such as store locations and opening times, or event information such as start times, then this style of caching is perfect. The capability even allows a ‘similarity threshold’, enabling you to fine-tune what is and isn’t considered a similar request.
The chart below shows the overall traffic with caching enabled, and we can see that the total token usage within the OpenAI service is now only half of what it originally was.
This caching comes with some warnings tho - firstly it requires the use of an Azure Redis Enterprise cache, which is not a cheap resource, and secondly it uses your OpenAI service as part of the caching process, so could possibly increase your overall cost.
Overall these new Generative AI capabilities in Azure API Management make it much easier for organisations to govern their usage of Azure OpenAI. The new metrics and rate limiting capabilities allow you to control access per user or per application, and with the right use case the caching capability could allow you to heavily reduce your token consumption.